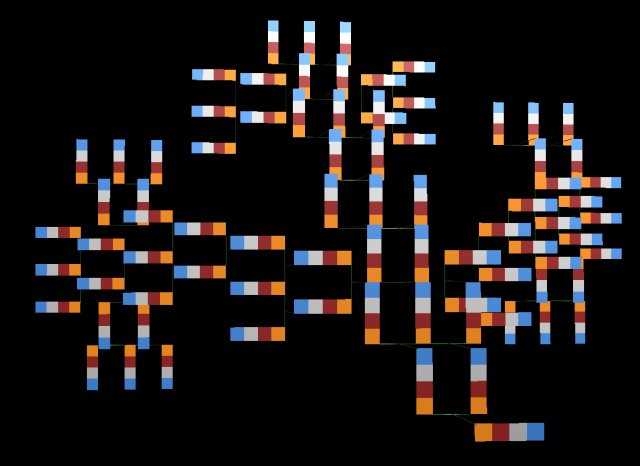
Project Description
The details of this proposal require a basic understanding of the structure of the Rhizome Artbase. Please consult the online documentation, and discuss with Mark and Alex where clarification is necessary.
When I began to conceptualize an alternative interface to the Rhizome Artbase, I naturally went to the Artbase to do some in-depth "poking around." I discovered immediately that there were far more works in the database than I ever expected, and that finding the things I might be interested in, was an extremely daunting task. I could of course hit the "big names" and access work I was already familiar with, but finding work I didn't already know, tracking down the obscure and sublime piece, was a process far too similar to slogging through the thousands of returns from a Google search. I then imagined myself as a first time viewer of Net Art, someone with no familiarity of the topic, and wondered where such a person could possibly begin. If you know nothing, what do you look at? What do you search for? I shuddered at the thought that this problem will only compound itself as time goes by, and more and more works are included in the Artbase. I thought that there must be a way to sift through the database and retrieve entities in a highly refined way, present these entities in a manner that was Net Art in and of itself, and base the selections not on a typical hierarchy of popularity or "expert" selectivity. Drawing from my corporate experience with relational databases, and my continuing interest in genetic solutions, I hit upon the notion of a "Context Breeder."
Context Breeder is a browser based Java applet and a stand alone java application for the collection and dynamic display of Artbase objects on the viewer's home computer. Using genetic algorithms implemented in a client based agent, Context Breeder curates intelligent selections of works and texts from the Rhizome Artbase. Context Breeder is a dynamic, distributed system for interfacing with the Artbase, extending the database (rhizomatously) onto the users' computers through extensions to the existing Artbase indexing. The activities of each individual user of the Context Breeder effect the results of other users. As new visitors add parameters, and as existing users change parameters, the output for all users changes both visually and contextually. Context Breeder is a constantly evolving pool of references to Artbase objects, each user having their own set of references similar to bookmarks, but bookmarks they don't explicitly create.
The Interface begins with a user's initial selection of four Artbase objects. The initial four objects the user selects may simply be the user's "favorites." They could also be four objects that relate to a certain theme like multi-user, or a technology like java, or perhaps they are simply random. If one is a first-time visitor to the Artbase, one receives a default sequence consisting of an art object that has been recently added to the Artbase, a recent text object, and two objects from a list of "well known" objects. The "well known" list initially consists of perhaps 20 objects selected by Rhizome, but over time the actions in the gene pool will modify this list. New users have a special role in the system as they are a constant source for the injection of "genetic diversity." The four objects then become the seed to a genetic sequence that is added to a pool containing sequences created by other users of the Artbase. The user's sequence subsequently "breeds" with other sequences in the pool. The offspring are then evaluated for fitness, and given a life span. In a sense, the offspring represent a set of "search results" and exist as such for the time of their life span. The benefit for the user is that a small initial "seed" will produce a refined selection of related objects, and that these objects are not from a specific list that any one person defines, but are a constantly evolving set of associations created by the sum total of all Artbase users, and their individual interests. The nature of the system is such that it will work equally well for a Mark Napier as it will for a Max Herman.
Once our user has made the initial selection of four objects, the agent goes to work. At the heart of the agent is a genetic crossover algorithm. Genetic software is highly effective at evaluating large amounts of data to produce an "answer" in a short period of time. For example, consider the traveling salesman problem. A salesman needs to make a number of stops around town and wants to plan the shortest route that fits them all in. A simple crossover algorithm is quite effective to arrive at the shortest route, and is far more efficient than a "brute force" iterative approach. In the case of our agent, the algorithm is "seeded" with the four unit sequence of object_ids. The agent then queries the existing gene pool for "matches." These are cases where one or more object_ids match in two sequences. The return set of sequences are ranked according to the number of matches. Threshold values are then applied to classify the sequences. Classification consists of "Twins" where the sequences are identical, "Siblings" where three out of four objects match, "Cousins" where two objects match, and "Friends" where one object matches. Twins, Siblings, Cousins, and Friends are immediately returned to the viewer, thumbnails and brief text are displayed in a spherical interface similar to my previous works EARTH and glasbead (in the case our agent, the viewer will be inside looking out, rather than outside looking in as in glasbead). For very old computers where not even a Java rendering can function, a plain html presentation will also be available. Below is an example of classification using thumbnails extracted from the Artbase.
CLASSIFICATION:
THIS USER 


TWINS
USER_ID B
THIS USER
SIBLINGS
USER_ID C 
USER_ID D 
THIS USER
COUSINS
USER_ID E 
USER_ID F 
THIS USER
FRIENDS
USER_ID G
USER_ID H
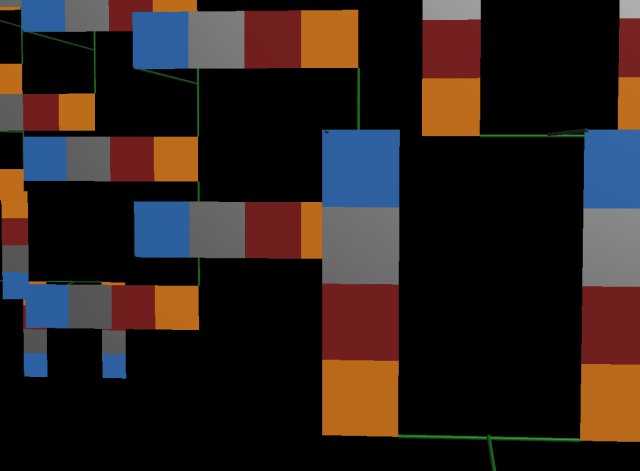
It is a safe assumption that sequences similar to our user's sequence contain art objects and texts that our user will likely be interested in. The speed at which the sequences are returned, based on exact index matching, will provide practically immediate return of these objects and demand little of the server. Most of the actual "search" processing will occur locally on the user's computer as what is being searched for is not text and keywords, but a table of indexes that have been downloaded to the local machine. The user will see a set of objects that relate to their initial seed set, and can access the works by clicking on the thumbnails. After the quick return and display of Twins, Siblings, Cousins, and Friends, our user's sequence begins to "breed" with the returned Friend sequences. Performing a genetic crossover algorithm, two new "Offspring" sequences are produced. The corresponding database information is retrieved and is subsequently processed in depth, comparing similarity within each object's database record, ranking the sequence according to this similarity, and ascribing a life span to the sequence. The life span represents how long the sequence will exist within the pool, and for how long this sequence will be accessible to other users. Below is a demonstration of this crossover algorithm.
GENETIC CROSSOVER
THIS USER
AND
USER_ID E
CREATE TWO OFFSPRING:
OFFSPRING 1
THIS USER
+
USER_ID E
OFFSPRING 2
USER_ID E
+
THIS USER
The crossover algorithm takes the first two objects from one sequence and the last two objects from the other sequence, swapping their positions to create a new offspring sequence. It then takes the last two objects of the first sequence, and the first two objects of the second sequence, swapping again, to create a second offspring sequence. The "Parent" user ids are appended to the new sequences, establishing a join between these two users.
It is the nature of agent software to always be running in the background (thus the advantage of a stand alone Java application, though the same processes will occur in a browser based applet version). When breeding takes place, both agents are notified. For example, if you have your agent running in the background, and another user breeds with your sequence (or one of your offspring sequences) the results of this action are immediately displayed in your agent. My initial thought is to also trigger a "giggle" sound (though I imagine the specific sound could be selected by the user, a "giggle" seems appropriate). Because you are notified only when an association is made that relates to your initial sequence, it is a safe assumption that the association interests you. The beauty of this system is such that the moment a user adds or modifies a sequence, or the moment any new offspring are produced, there is a cascading repercussion throughout the whole system. Two users may independently of me, produce an offspring that is a new "Friend" of mine. My agent notices this and subsequently breeds with the new Friend to produce new offspring, which in turn may be classified as Friend sequences to other users, and so on, and so on. The visual outcome is a constantly evolving datascape of object references, with the understanding that what is shown are entities that one will likely be interested in seeing, and that the return of these entities required only the minimum of initial "seeding" on one's part.
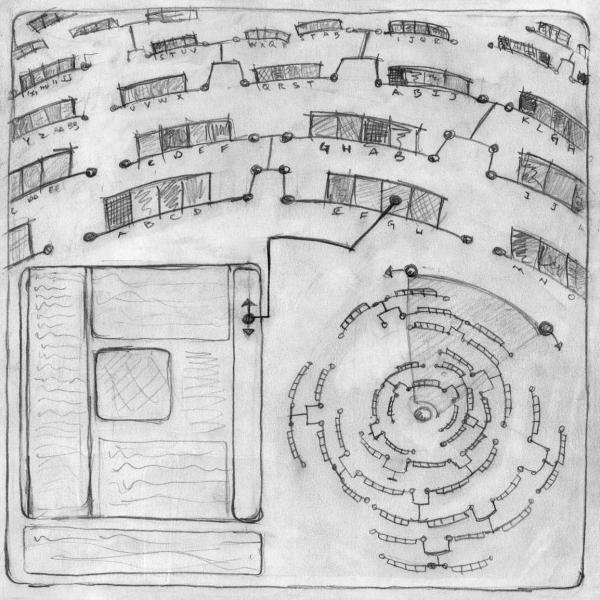
The visual manifestation
of these back-end processes is a continuation of my interest in spherical
interfaces. Normally, in a two dimensional hierarchical structure,
each element in the hierarchy, branched in an outline form, has the
same basic "weight" on the screen. Each is a line of text, of equal
height, the sole differentiation being its indentation in the tree.
If one imagines a branching file tree expanded into three dimensions, the
"root" being the center of a sphere with sub-elements expanding in axes
from this central core, one is presented with an interface that becomes
immediately discernible, with the most significant elements closer to the
center, and the least significant expanding outward from the central core.
If ones viewpoint is located at this central core, the most significant
information is close at hand, the least significant receding into the distance.
The underlying structure of Context Breeder lends itself perfectly to this
visual manifestation as distant relations will locate themselves down an
axis of a "family tree," while close relations will position themselves
centrally. All the offspring, and offsprings' offspring, radiate
in numerous axes expanding from the core. Each branch is easily accessible
by rotating the entire structure so an axis is centered within the field
of view. Traversal of a large dataset simply becomes a matter of
traveling down a spoke of this sphere. Because as one extends the
radius of a sphere its circumference increase exponentially, as one travels
outward from the center there is an ever increasing space to render information.
As the genetic pool of associations modifies itself, the branches will
constantly expand and contract, shift and rotate, to create a swirling,
pulsing form. This basic notion of a spherically branching interface
is something that I have been contemplating for many years, though I have
not found until now, an application where it would be truly efficacious.
In "glasbead" I used the rotational properties of a sphere as an intuitive
timing element for sound triggering, and here I will take advantage of
the expansive element of a sphere as a means to the intuitive access of
relational information. The relational aspect of Context Breeder's underlying
structure, and its natural representation through iconic thumbnails, dovetails
perfectly with the properties and advantages of such a spherical interface.
Project Timeline and Milestones
Context Breeder can be divided into specific project milestones. It is my intent to build Context Breeder for maximum platform compatibility, thus the necessity for a Java based solution.
Milestone
1:
Establish
the appropriate environment for cross platform delivery.
Thus far my work
with Java has been focused on the compiler version 1.3.2, aka Java
2. Though compatible with PC's, Linux, and Mac OS X, Java 2 does
not function on Mac OS 9 and older. The real-time Java 3d libraries
I have been using are compatible with Java 1 and will run on a Mac provided
they are properly compiled. The first major effort will be securing
a development environment that compiles and is releasable to all the mentioned
platforms. I expect that this milestone will ultimately involve a
full week of concerted effort, as resources for testing and implementation
of the various operating systems will need to be diligently accumulated.
Milestone
2:
Create
the necessary back-end processes for data access.
Having considerable
professional experience with relational databases I foresee little trouble
accessing the existing Rhizome Artbase, however a few extensions to the
database will need to be established, either inside the database itself
or as a parallel cloned database on one of the many available web systems.
The Java data agent will need to be authored and made fully robust, and
heavily tested. I think it reasonable to require two weeks for the
creation of a seamless, efficient, and fully tested Java based access mechanism.
Milestone
3:
Build
the genetic algorithms.
I have previously
worked with these algorithms in projects such as ecosystm and ecogame,
and the requirements of a four gene sequence crossover are minimal, so
I expect the authoring of the genetics to take little more than a week.
However, the fitness heuristic, ultimately the most critical aspect of
the work, is an element that requires a significant amount of "fiddling."
No two heuristics are alike, and every case requires a custom solution
that is usually arrived at after considerable experimentation. Therefore,
once a working system is in place, which again should require no more than
a week, at least 2 additional weeks should be spent simply "messing around"
with the fitness heuristic and evaluating results. This is really
where the "code art" exists.
Milestone
4:
Make
the GUI
Most of the code
required for the spherical interface exists in both glasbead and EARTH,
though i'll need to translate what I need into Java. I think it reasonable
to require one week to create a functioning interface, and an additional
week for perfection, testing, and usability concerns.
To summarize, I reasonably expect to complete the project in 8 to 10 weeks of full-time effort.